Nucleon Atomic
Scalable Distributed Data Processing Framework
The Nucleon Atomic Framework is a cutting-edge platform designed for the distributed processing of large datasets across clusters of computers. By leveraging the MapReduce programming model, it provides unparalleled scalability, performance, and flexibility for handling modern data challenges, whether working with files, relational databases, or NoSQL systems.
Core Features
- Distributed Computing with MapReduce
Nucleon Atomic enables the efficient distribution and parallel processing of data-intensive tasks using the MapReduce paradigm. Key advantages include:- Map: Processes and organizes raw data into manageable chunks.
- Reduce: Aggregates and summarizes results from distributed computations.
These processes are seamlessly orchestrated across worker nodes, ensuring fast and reliable data processing.
- Data Source Compatibility
- File Systems: Process and analyze files of any size by distributing their contents across computing nodes.
- Relational Databases: Execute MapReduce operations directly on database tables and views, leveraging structured data for analysis.
- NoSQL Databases: Handle unstructured and semi-structured data, making it ideal for modern, dynamic applications.
- Scalable Architecture
The framework is designed to scale from a single local server to hundreds of machines, each contributing local computation and storage. This ensures robust performance across workloads, from small projects to enterprise-scale deployments. - Microsoft Technology Integration
Built primarily in C#, Nucleon Atomic utilizes Microsoft WCF (Windows Communication Foundation) for distributed communication. It is optimized for Windows environments, offering:- Native .NET support.
- High-performance data streaming and task execution.
- Flexibility for Developers
While .NET/C# is the default language for MapReduce tasks, Nucleon DCF (Distributed Computing Framework) supports any programming language, allowing developers to use their preferred tools for implementing “map” and “reduce” logic. - Inspired by Industry Standards
Nucleon Atomic’s design draws inspiration from industry-leading platforms like Apache Hadoop and Apache Spark, while optimizing them for the Microsoft ecosystem.
How It Works
- Master Node: Manages job scheduling, distributes tasks to worker nodes, and aggregates results.
- Worker Nodes: Execute map and reduce tasks, handling data motion and local computation.
The Nucleon Atomic Framework ensures reliability through built-in redundancy and fault tolerance, enabling smooth operations even in large-scale deployments.
Why Choose Nucleon Atomic?
- High Scalability: Seamlessly scale from single servers to hundreds of machines.
- Versatility: Process data from diverse sources, including files, relational databases, and NoSQL systems.
- Performance-Driven: Optimized for Windows with .NET and WCF technologies.
- Developer-Friendly: Supports multiple programming languages for MapReduce implementation.
- Industry-Inspired Innovation: Combines the best of Apache Hadoop and Spark with Microsoft optimizations.
Transform the way you handle data with Nucleon Atomic, the scalable and flexible solution for distributed data processing.
Contact us today to learn how Nucleon Atomic can elevate your data processing and analytics capabilities!
Modules
The core Nucleon Atomic Framework is composed of the following essential modules, each designed to support specific aspects of data processing and distributed computing:
- Datasource Connections
This module enables seamless connectivity with any data source. Whether you are working with traditional databases, modern data lakes, or other data storage systems, Datasource Connections allow you to integrate your data environment effortlessly into the Nucleon Atomic framework for processing and analysis. - Atomic DCF (Distributed Computing Framework)
Built using Microsoft WCF (Windows Communication Foundation) technology, this module provides the foundation for distributed computing. It allows developers to construct robust master/worker node architectures for large-scale, parallel processing tasks. Atomic DCF ensures efficient communication, fault tolerance, and redundancy among distributed nodes, making it ideal for handling massive workloads. - Atomic MapReduce
This is the framework’s implementation of the MapReduce programming model, specifically tailored for large-scale data processing. The module is designed to:- Perform distributed mapping and reducing tasks efficiently.
- Handle the partitioning of input data and manage intermediate outputs.
- Ensure parallel task execution across nodes for faster processing times.
With Atomic MapReduce, users can analyze vast amounts of data quickly and effectively, making it a powerful tool for real-time insights and decision-making.
Database System
The MapReduce application integrates seamlessly with database systems to execute Map and Reduce code directly on database tables or views. Key functionalities include:
- Data Processing: The application can process structured data by applying mapping and reducing logic to tables and views in the database.
- Distributed Execution: The database results (such as query outputs) are automatically partitioned and distributed across the worker server nodes for parallel processing.
- Filtering Results: After the Map phase is executed on the distributed nodes, the intermediate results are aggregated, and final filtering or summarization is performed on the Main Node to produce the final output.
This architecture enables high-performance analytics and processing of large-scale datasets stored in database systems, optimizing query efficiency and computation time.
File System
The MapReduce application also supports processing data stored in file systems. It executes Map and Reduce code to handle unstructured or semi-structured data files. The core features include:
- File Processing: The content of files is parsed and processed in distributed chunks, enabling efficient handling of large files or collections of files.
- Distributed Execution: File data is split and distributed across server nodes, where the Map phase processes individual file segments.
- Result Aggregation: The Main Node collects the outputs from the worker nodes after the Map and Reduce phases, applying any necessary final filtering or aggregation.
This approach is ideal for processing log files, text data, and other non-relational data formats, ensuring scalability and performance for file-based data analysis.
These capabilities make the MapReduce application versatile, allowing it to handle both structured (database) and unstructured (file system) data with equal efficiency. Let me know if you’d like to expand on specific use cases or add examples!
Main Features
The Nucleon Atomic Framework offers a robust set of features for distributed computing and data processing, making it versatile and powerful for handling large-scale datasets. Key features include:
- Job Distribution, Reduction, and Finalization
- Automatically distributes computational jobs across multiple worker nodes for parallel execution.
- Executes Map tasks to process and organize data and Reduce tasks to summarize and aggregate results.
- Centralizes and finalizes processed outputs on the master node for efficient result delivery.
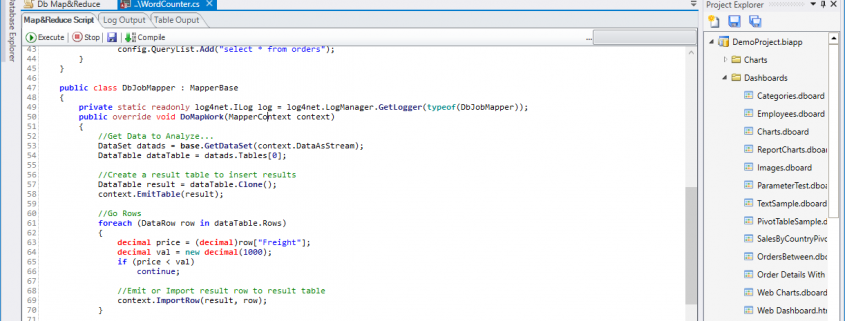
- C# Code for Map & Reduce
- Provides native support for writing Map and Reduce logic in C#, leveraging the full power of the .NET ecosystem.
- Simplifies the development of distributed applications while enabling advanced customization and performance optimization.
- Integrates seamlessly with the framework’s Atomic DCF module to handle distributed execution.
- Query, Filter, Compute, and Visualize Results
- Offers tools to query large datasets, apply filtering conditions, perform computations, and generate visualizations.
- Supports interactive workflows, making it easier for users to extract insights from their data.
- Provides compatibility with BI tools for advanced reporting and analytics.
- Map & Reduce to File System
- Enables distributed processing of file-based data, including unstructured and semi-structured formats.
- Efficiently handles large files by splitting and processing them in parallel across server nodes.
- Aggregates and finalizes results on the master node for streamlined analysis of file system data.
- Map & Reduce to Database Tables
- Directly executes Map and Reduce operations on database tables and views.
- Distributes query results across worker nodes for parallel processing.
- Supports structured data processing with powerful filtering, computation, and summarization capabilities.
These features ensure scalability, flexibility, and high performance, making the framework suitable for a wide range of data processing and analytics scenarios.